A writeup of the Cryptopals Crypto Challenge Set 2.
2026: new year, new goals and why not, new life. Only one constant in the equation: keep pushing.
In this post, we'll analyze the most challenging problems found in set 2 of Cryptopals.
For most of the levels, we will adhere to the following protocol:
-
Needed Prerequisites
-
Problem Abstraction
-
The Exploit: A deep dive into the vulnerability
-
Post-mortem: Key takeaways
I solved this set several months ago and I found it very stimulating.
Somehow Cryptopals made me grow as a person, allowing me to glimpse the true power of programming and mathematics, the fact that code is nothing but thought taking form.
There's no better feeling than when you start reasoning about a problem from scratch and like an LLM in thinking mode your mind starts firing hypotheses until you find the right solution.
That's why I suggest all readers solve the set independently before seeing the solution.
Levels 9 and 15 (Pad and Unpad)
Prerequisites
A Block Cipher is a deterministic cryptographic primitive defined as a function $E$ that accepts two inputs: a $k$-bit key $K$ and an $n$-bit plaintext block $P$.$$E : {0,1}^k \times {0,1}^n \to {0,1}^n$$ The output is an $n$-bit ciphertext block $C$, computed as:$$C = E(K, P) = E_K(P)$$
The decryption function $D$ is defined simply as the inverse of the encryption function.
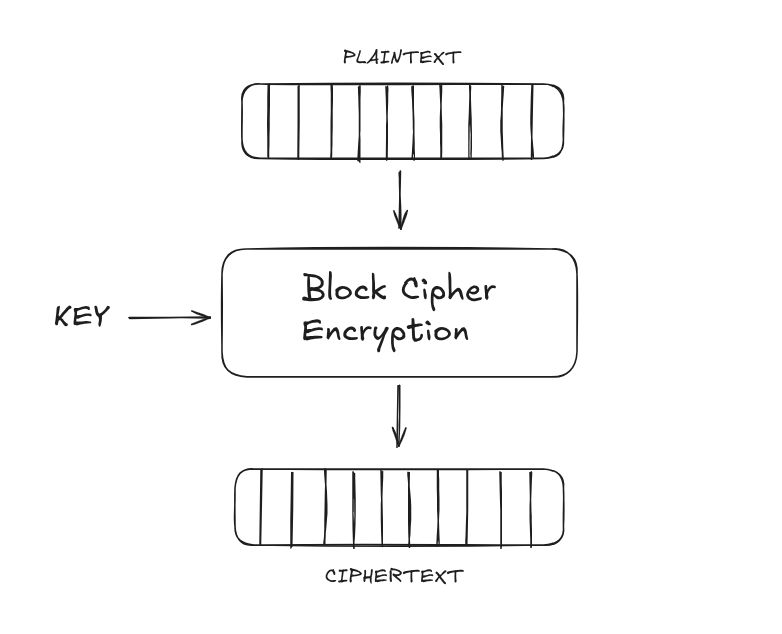
At a high level, we can conceptualize a block cipher by contrasting it with a stream cipher.
A stream cipher works bit by bit, while a block cipher works in blocks of $n$ bits.
The Problem
With this framework established, two immediate questions arise: how do we handle cases where the plaintext is shorter than the block size? And conversely, how do we proceed when the plaintext stream exceeds the single block capacity?
The solution
To address the first question we introduce the concept of a Padding Scheme.
Formally, this is a deterministic function that appends data to the plaintext to ensure its total length is an exact multiple of the block size $n$. While there are many padding standards, the dominant standard in modern cryptography and the one relevant to Cryptopals is PKCS#7.
Levels 9 and 15 task us with implementing the padding and unpadding primitives, but before we dive into the implementation, let's deconstruct the mechanics of PKCS#7.

The idea is that we don't just fill space; we fill it with metadata about the fill itself!
The algorithm is simple: if we need to add $N$ bytes of padding to reach the block boundary, we append $N$ bytes, where each byte has the value $N$.$$P_{padded} = P \ || \ \underbrace{N, N, \dots, N}_{N \text{ times}}$$ This creates a crucial invariant: the last byte of the padded message always tells us exactly how many bytes to strip away during decryption.
An example, for the sake of simplicity let Block Size = 4 bytes.
Let's visualize how we pad different messages to align with a 4-byte block boundary.
-
Message: "A" (1 byte)
- Gap: 3 bytes needed.
- Padding:
0x03, 0x03, 0x03 - Result:
41 03 03 03("A\x03\x03\x03")
-
Message: "AB" (2 bytes)
- Gap: 2 bytes needed.
- Padding:
0x02, 0x02 - Result:
41 42 02 02("AB\x02\x02")
-
Message: "ABC" (3 bytes)
- Gap: 1 byte needed.
- Padding:
0x01 - Result:
41 42 43 01("ABC\x01")
Now we reached an Edge Case: What if the message is already a multiple of the block size (e.g., "ABCD")?
If we added nothing, the decryption function wouldn't know if the last bytes were real data or padding. Therefore, we must add a full dummy block consisting entirely of padding bytes, therefore:
- Message: "ABCD"
- Gap: 4 bytes needed.
- Padding:
0x04, 0x04, 0x04 0x4 - Result:
41 42 43 44 04 04 04 04("ABCD\x04\x04\x04\x04")
Armed with this logic and a fundamental grasp of modular arithmetic, the generalization becomes trivial. Here is the implementation.
def pkcs_7(to_pad: bytes, block_size: int):
pad = len(to_pad) % block_size
missing = block_size - pad
return to_pad + bytes([missing]) * missing
For the unpadding routine, the logic is inverted. We strictly interpret the final byte as a length indicator and strip the corresponding suffix. Crucially, this operation must only proceed after asserting that the padding is formally valid.
def unpkcs_7(padded: bytes, block_size: int):
pad = padded[-1]
if pad == 0 or pad > block_size:
raise Exception("Invalid padding value")
if len(padded) % block_size != 0 or not padded.endswith(bytes([pad]) * pad):
raise Exception("Invalid pkcs7 encoded string")
return padded[:-pad]
As for the second inquiry regarding larger plaintexts: see you in Level 11.
Level 11 (Detect Mode)
Prerequisites
We left one critical question unanswered: How do we handle data that exceeds the block size? If our message is 1MB long and our block cipher only encrypt 16 bytes at a time, we need a strategy to feed the data into the it safely.
In cryptography, this strategy is called a Mode of Operation. While modern cryptography favors authenticated modes like GCM or Chacha20-Poly1305, Cryptopals starts us off with the two "grandfathers" of block encryption.
Understanding them is mandatory to understanding why modern systems are built the way they are. Also, make sure you understand the formulas and diagrams, as they are necessary for understanding future attacks.
- ECB (Electronic Codebook)
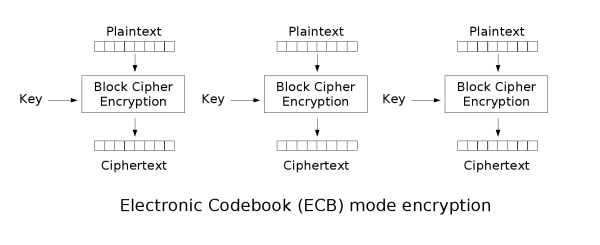
This is the simplest possible mode. You divide the message into blocks and encrypt each one independently with the same key.
$$C_i = E_K(P_i)$$
This mode is stateless and deterministic.
It has an interesting property: if $B_0 == B_1$, then $E_K(B_0) == E_K(B_1)$, Patterns in the input persist in the output.
Despite the simplicity of this mode, it shouldn't be used because while it hides the specific bytes, it could leak other informations, like the high level structure of the plaintext, as we can see in this famous example:

In this case, we can still recognize the penguin figure, as blocks of bytes with the same value will be encrypted, producing the same ciphertext.
- CBC (Cipher Block Chaining)
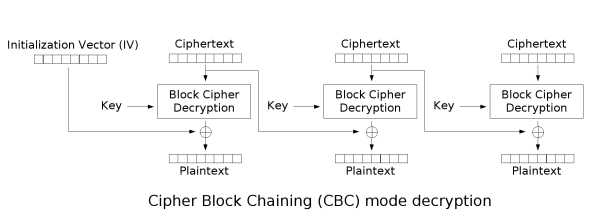
To fix the pattern leakage of ECB, an idea could be that the encryption of block $N$ should depend on the result of block $N-1$.
The mechanism is simple: Before encryption, we XOR ($\oplus$) the current plaintext block with the previous ciphertext block. This mode "chains" them together.
Thinking about this, one edge case stands out: since the first block ($P_1$) has no previous ciphertext to chain with, we must generate a random block called the Initialization Vector (IV) ($C_0$).
This way of working gives us this property: Even if $B_0 == B_1$, the encryption context differs ($IV$ or $C_{prev}$), ensuring $C_0 \neq C_1$.
If the first block has index 1, the mathematical formula for CBC encryption is: $$C_i = E_K(P_i \oplus C_{i-1}), \quad C_0 = IV$$ Conversely, the formula for CBC decryption is: $$P_i = D_K(C_i) \oplus C_{i-1}, \quad C_0 = IV$$
The problem
def guess_mode(plaintext: bytes) -> tuple[bytes, int]:
# Simulation of the black box function
key = os.urandom(16)
is_ecb = random.randint(0, 1)
if is_ecb:
cipher = CustomEcb(key)
else:
iv = os.urandom(16)
cipher = CustomCbc(key, iv)
# This shift alignment by prepending and appending random bytes
payload = pkcs_7(
os.urandom(random.randint(5, 10))
+ plaintext
+ os.urandom(random.randint(5, 10)),
16,
)
ciphertext = cipher.encrypt(payload)
return (ciphertext, is_ecb)
In this level we are tasked with treating a function as a "Black Box" (or Oracle). This Oracle is hostile to analysis in two ways:
-
Unknown Alignment: It prepends and appends random bytes to our plaintext, shifting the alignment.
-
Mode Uncertainty: It randomly toggles between encrypting with ECB and CBC (50% probability each).
What we should do is writing a detector that queries this Oracle and reliably determines which mode is currently active.
The solution
The intuition for solving this problem is that since we control the input plaintext, we can force two ciphertext block to become the same if we are in ECB mode.
The challenge is the random prefix (5-10 bytes), which shifts our data, preventing us from knowing exactly where our blocks start. However, we don't need to know where the blocks start; we just need to guarantee that they eventually align. If we craft an input consisting of a sufficiently long repeating pattern, like of length 48 , we can saturate the buffer.
Let's analyze the worst-case geometry (Prefix = 10 bytes, Block Size = 16 bytes)
- The prefix 10 bytes (occupies part of Block 1).
- Our Input: 6 bytes (completes Block 1) + 16 bytes (Block 2) + 16 bytes (Block 3) + ...
By sending at least 3 blocks worth of identical bytes, we mathematically guarantee that at least two full consecutive blocks of the underlying plaintext will be identical, regardless of the random prefix length!
We can use this information as a discriminant:
- In the ECB case, since $P_2 = P_3$, the cipher outputs $C_2 = C_3$. We observe duplicate 16-byte chunks in the ciphertext.
- In the CBC: Due to the chaining mechanism ($P_2 \oplus C_1$ vs $P_3 \oplus C_2$), the outputs will be radically different. $C_2 \neq C_3$.
This concept can be easily generalized, what we need to do is just find a big input that allow two block to be the same, and check for repeating blocks.
def get_blocks(buf, block_size):
assert len(buf) % block_size == 0, "Buf len is not a multiple of block_size"
return [buf[i : i + block_size] for i in range(0, len(buf), block_size)]
def detect_mode(ciphertext):
blocks = get_blocks(ciphertext, 16)
return len(blocks) != len(set(blocks))
Level 12 (Byte-at-a-Time Decryption, simpler version)
Prerequisites
Here things are getting interesting, to execute this attack, we rely on the core failing of ECB (Electronic Codebook) discussed in the previous level: determinism.
We assume the ability to inject chosen plaintext into the system and observe the output, a scenario formally known as a Chosen Plaintext Attack (CPA).
Problem Abstraction
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
import os
ECB_ORACLE_KEY = os.urandom(16)
SECRET = b"""I am a secret credential, you aren't allowed to read this!!!"""
def ecb_oracle(plaintext: bytes) -> bytes:
cipher = AES.new(ECB_ORACLE_KEY, AES.MODE_ECB)
response = pad(plaintext + SECRET, 16)
return cipher.encrypt(response)
We are facing an Oracle defined as:$$C = E_K(P \ || \ S)$$ Where:
- $P$ is the attacker-controlled plaintext (our input).
- $S$ is the target secret (unknown to us).
- $||$ denotes concatenation.
- $K$ is a fixed, unknown key.
Our goal is to extract $S$ entirely, byte by byte, using only the ability to query this function.
The exploit
We will manually simulate the attack to see the pattern emerge. The Scenario:
- Block Size ($n$): 6 bytes (chosen for simplicity).
- Target Secret: "dontreadme"
- Padding: Since the secret is 10 bytes, PKCS#7 adds 2 bytes of 0x02.
- Oracle Function: $O(input) = E_K(input \ || \ secret \ || \ padding)$
- Although we already know, we are going to probe the blackbox, discovering the block size. The idea is simple, we inject inputs of increasing length and monitor the output size.
Here an example of that increasing length:
- Input "" $\to$ Output size 12 (2 blocks:
dontre | adme\x02\x02). - Input "A" $\to$ Output size 12.(2 blocks:
adontr | eadme\x01). - Input "AA" $\to$ Output size 18 (3 blocks
aadont | readme | \x06\x06\x06\x06\x06\x06).The jump from 12 to 18 tells us two things: the Block Size is 6, and we have pushed the padding into a new block.
- Input "" $\to$ Output size 12 (2 blocks:
def discover_block_size(oracle, max_block_size) -> int:
# another idea is using gcd! gcd(x*i,x*j) = x*gcd(i,j), find x
start_len = len(oracle(b""))
for guessed_block_size in range(1, max_block_size + 1):
curr_len = len(oracle(b"A" * guessed_block_size))
#if size is different, calculate the delta!
if curr_len != start_len:
return curr_len - start_len
raise Exception("Unable to discover block size")
Now that we got the block size, we can start the Byte-at-a-Time Decryption!
We are going to start by crafting an input block where only the last byte is unknown.
Finding byte 1 ('d')
We need 5 bytes of padding ($BlockSize - 1$) to isolate the first secret byte.
- Input:
AAAAA - Oracle State:
[A A A A A d] | [o n t r e a] ... - Target: We capture Block 0: $C_{target} = E_K(\text{AAAAAd})$.
- The Attack: We compute $E_K(\text{AAAAA} + x)$ for $x \in 0..255$.
- Does
AAAAA+ a match $C_{target}$? No. - Does
AAAAA+ b match $C_{target}$? No. - ...
- Does
AAAAA+ d match $C_{target}$? YES.
- Does
- Recovered:
d
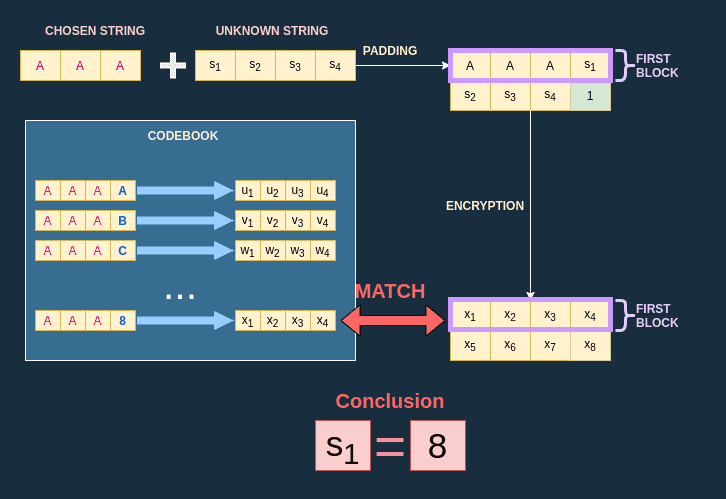 An image showing the bruteforce just described.
An image showing the bruteforce just described.
Finding byte 2 ('o')
Now 4 bytes of padding ($BlockSize - 2)
- Input:
AAAA - Oracle State:
[A A A A d o] | [n t r e a d] ... - Target: We capture Block 0: $C_{target} = E_K(\text{AAAAdo})$.
- The Attack: We use the known secret (
d) and brute-force the rest. We compute $E_K(\text{AAAA} + \text{d} + x)$.- Only $x = \text{'o'}$ produces the matching ciphertext.
- Recovered:
do
...We keep iterate until we reach the end of the first block...
Finding byte 6 ('e'), the last char of the first block
- Input:
""(Empty string) - Oracle State:
[d o n t r e] | [a d m e \x02 \x02] ... - The Attack: Brute-force $E_K(\text{dontr} + x)$.
- Recovered:
dontre
After that, all we need is just repeat what we already did to recover the first block!
More precisely, We have filled the first block, in order to find the next byte, we must push the 7th byte of the secret into the last position of the first block relative to our padding.
We reset the padding to 5 bytes (AAAAA), exactly like in Phase 1.
- Input:
AAAAA - Oracle State:
[A A A A A d] | [o n t r e a] | [d m e \x02 \x02 ...] - Target: This time, we are interested in Block 1 (the second block).
- $C_{target} = \text{Block}_1 \text{ of } E_K(\text{AAAAA} + \text{secret})$.
- This block corresponds to
ontrea.
- The Attack: We construct a guess using the last 5 known bytes (
ontre) + $x$.- We calculate $E_K(\text{AAAAA} + \text{dontre} + x)$.
- This produces:
[AAAAAd] [ontreX]. - We compare the second block of our guess against the target.
- Recovered:
dontrea
Continuing with this approach, we will successfully recover the string dontreadme !
An optimization
If you look closely at the walkthrough above, a pattern of inefficiency emerges.
- Step 1 (Byte 1): We sent
AAAAAto the Oracle to get the target. - Step 7 (Byte 7): We sent
AAAAAto the Oracle again to get the target (we just looked at a different block index). - Step 13 (Byte 13): We would send
AAAAAagain.
In a real network exploit, round-trip time is expensive. We are repeating the same queries.
By looking at the attack i wrote on paper, i noticed this pattern and got the idea to add a cache: we can pre-calculate the entire state of the system at the very beginning.
It works like that: before recovering a single byte, we ask the Oracle to encrypt:
AAAAA→ Store asCache[5]AAAA→ Store asCache[4]AAA→ Store asCache[3]AA→ Store asCache[2]A→ Store asCache[1]""→ Store asCache[0]
Using this cache:
- when we need to crack Byte 1, we need 5 bytes of padding. We don't call the server; we just look at
Cache[5]. - When we need to crack Byte 7, we calculate the padding: $6 - (7 \bmod 6) - 1 = 5$ bytes. We again just look at
Cache[5].
This reduces the number of network requests significantly, making the exploit much faster. By searching online, i found version of this attack even more optimized than mine, but as of first write, i am very happy with the result obtained.
Here is the full implementation, combining the Oracle simulation, the block size discovery, and the optimized attack logic.
def break_ecb_oracle(oracle) -> bytes:
block_size = discover_block_size(oracle, 16)
if detect_ecb(oracle, block_size):
recovered_plain = b""
results_cache = []
# Optimization, we just need this precomputed ciphertext to bruteforce correctly
for i in range(block_size):
crafted = b"A" * i
results_cache.append(oracle(crafted))
n_blocks = len(results_cache[0]) // block_size
for cur_block in range(n_blocks):
for j in range(1, block_size + 1):
for bruted_char in range(0xFF + 1):
crafted = (
b"A" * (block_size - j) + recovered_plain + bytes([bruted_char])
)
# This allow us to isolate the block we want to break
start = block_size * cur_block
end = block_size * (cur_block + 1)
if (
oracle(crafted)[start:end]
== results_cache[block_size - j][start:end]
):
recovered_plain += bytes([bruted_char])
break
return recovered_plain
else:
raise Exception("Oracle is not encrypting in Ecb Mode")
Post Mortem
-
NEVER use ECB mode. There is almost no scenario in modern computing where ECB is the correct choice. If you are not using an Authenticated Encryption mode (like GCM), you are likely doing it wrong.
-
Composability matters. The encryption algorithm (AES) is mathematically secure. The Key is random and secure. However, the system architecture, combining attacker input directly with a secret in a deterministic mode is catastrophically broken.
-
Leakage is Cumulative. We didn't break the key. We didn't solve a math problem. We simply asked the server 256 times "Does the secret this character? Given enough queries, a "dumb" oracle reveals everything.
Level 14 (Byte-at-a-Time Decryption, harder version)
Prerequisites
To solve this, you must have mastered Level 12. The core attack vector remains ECB Determinism (identical inputs create identical outputs) and the Sliding Window technique.
However, this level introduces a new complexity: Alignment. You must understand that block ciphers process data in chunks. If the data preceding your input doesn't fill a complete block, your input will be split across two blocks. Controlling this alignment is the key to the exploit.
Problem Abstraction
def ecb_oracle_harder(plaintext: bytes) -> bytes:
cipher = AES.new(ECB_ORACLE_KEY, AES.MODE_ECB)
response = pad(ECB_ORACLE_PREFIX + plaintext + SECRET, 16)
return cipher.encrypt(response)
The Oracle has evolved. It is now defined as:
$$C = E_K( \text{Prefix} \ || \ P \ || \ S )$$
Where:
- $P$ is your input (Attacker Controlled).
- $S$ is the Target Secret.
- Prefix is a random string of bytes. It is constant for this session, but its length and content are unknown to you.
In Level 12, if you sent "A", you knew exactly where that "A" would land (Byte 0 of Block 0).
Now, if len(Prefix) == 5, your "A" lands at Byte 5 of Block 0.
We cannot perform the dictionary attack if we don't know where our crafted blocks begin.
The Exploit
The idea to exploit this code, is that even if the prefix is variable, if the attacker can control the length of their input, they can inject padding bytes.
This forces the variable prefix to fill a complete block (or set of blocks). Once the prefix ends exactly at a block boundary, the attacker can use the standard attack to decrypt the server secret located at the end of the string.
The Fixup
We need to neutralize the random prefix. We don't care what the prefix contains, only how long it is. If the Prefix is 5 bytes long (and block size is 16), we need to inject 11 bytes of "junk" padding.
$$5 \text{ (Prefix)} + 11 \text{ (Fixup)} = 16 \text{ (One Full Block)}$$
Once we do this, the next byte we send will start exactly at index 0 of the next block. We have achieved alignment.
The actual Attack
Once we know the Fixup size, we treat the oracle exactly like Level 12, but with one change: we prepend the Fixup to every request, and we ignore the first $N$ blocks of "garbage" (Prefix + Fixup) when analyzing the output.
To measure the prefix, my idea is to create a block known to contain only "A"s.
After that we got this block, we then iterate i from 0 to 256. We send prefix + "A"*i.
We scan the output blocks. If we find the block full of "A" at block index j, we know that Prefix + i bytes exactly filled all blocks up to j.
Thus, (j + 1) * block_size is the total bytes consumed. Subtracting i (our input size) gives us the prefix length.
def find_prefix_len(a_encrypted, block_size):
"""a_encrypted is an encrypted block string made of full A"""
for i in range(256 + 1):
crafted = b"A" * i
blocks = get_blocks(ecb_oracle_harder(crafted), 16)
for j, b in enumerate(blocks, 0):
if b == a_encrypted:
return (block_size * (j + 1)) - i
raise Exception("Unable to find prefix len")
To align the blocks, i wrote this simply function that calculates what i called the "ceiling" multiple. If the prefix is 17 bytes, we need to reach 32. This function tells us where the next clean block starts.
def get_aligned_multiple(number, block_size):
q, r = divmod(number, block_size)
return (q + (1 if r else 0)) * block_size
After that, we just need to calculate prefix_len and needed_fixup (the "junk" padding needed to align).
So it is just matter to send: crafted = needed_fixup + padding + recovered + guess and selecting the right block!
def break_ecb_oracle_harder(oracle) -> bytes:
block_size = discover_block_size(oracle, 16)
if detect_ecb(oracle, block_size):
#find needed chars for fixup
#suppose that the size of prefix is in range [3;32]
a_encrypted = ecb_oracle_harder(b"A" * 256)[
16 * 4 : 16 * 5
] # we assume this block will be full of A's"
prefix_len = find_prefix_len(a_encrypted, block_size)
legit_start_block_index = get_aligned_multiple(prefix_len, block_size)
needed_fixup = b"A" * (legit_start_block_index - prefix_len)
# after finding the fixup, just add it and skip these blocks
recovered_plain = b""
results_cache = []
#precomputation
for i in range(block_size):
crafted = needed_fixup + b"A" * i
results_cache.append(oracle(crafted))
n_blocks = len(results_cache[0]) // block_size
for cur_block in range(n_blocks):
for j in range(1, block_size + 1):
for bruted_char in range(0xFF + 1):
crafted = (
needed_fixup
+ b"A" * (block_size - j)
+ recovered_plain
+ bytes([bruted_char])
)
#relative block
start = legit_start_block_index + block_size * cur_block
end = legit_start_block_index + block_size * (cur_block + 1)
if (
oracle(crafted)[start:end]
== results_cache[block_size - j][start:end]
):
recovered_plain += bytes([bruted_char])
break
return recovered_plain
else:
raise Exception("Oracle is not encrypting in Ecb Mode")
Post-mortem:
-
Offsets are not Security: Adding a random prefix (or salt) to the beginning of a message does not prevent decryption in ECB mode. It only adds a computational step (finding the length).
-
Attack Reusability: Complex attacks are often just simple attacks with a setup phase. By solving the "Alignment" problem, we transformed a Hard problem into an Easy one, basically reusing our previous code.
-
Controlled Input is Dangerous: The ability to inject data of arbitrary length allows an attacker to manipulate the internal state of the block processor, forcing alignments that the designer never intended.
Level 13 (ECB Cut and Paste)
Prerequisites
This level moves beyond passive decryption to active malleability. Again, you need to understand that in ECB mode, blocks are completely independent.
This implies that if you have two valid ciphertexts encrypted with the same key, you can swap, reorder, or remove blocks, and they will still decrypt validly.
Problem Abstraction
This vulnerability is the cryptographic equivalent of Insecure Deserialization or Parameter Tampering.
In early web implementations, developers often encrypted state cookies believing encryption provided integrity.
For example, imagine a shopping cart cookie item=123&price=100.
An attacker could "cut" the encrypted block for a cheap item's price and "paste" it onto an expensive item's cookie.
uid = 0
CUT_AND_PASTE_KEY = get_random_bytes(16)
cipher = AES.new(CUT_AND_PASTE_KEY, AES.MODE_ECB)
def profile_for(email: str) -> bytes:
global uid
# prevents trivial injection
safe_email = email.replace("=", "").replace("&", "")
encoded_cookie = f"email={safe_email}&uid={uid}&role=user"
uid += 1
return cipher.encrypt(pad(encoded_cookie.encode(), 16))
def parse_cookie(encrypted_cookie: bytes):
# decrypt and parses k=v pairs
encoded_cookie = unpad(cipher.decrypt(encrypted_cookie), 16).decode()
res = {}
for kv in encoded_cookie.split("&"):
k, v = kv.split("=")
res[k] = v
return res
We are dealing with a classic "structured cookie" scenario.
The system uses a profile serialization format similar to URL query parameters:
email=foo@bar.com&uid=10&role=user
The application provides an Oracle function profile_for(email) that:
- Sanitizes the input (strips
=and&to prevent trivial injection). - Formats the string with an
uidandrole=user. - Encrypts it using AES-ECB.
What we need to to is elevate our privileges by crafting a ciphertext that decrypts to a profile where role=admin.
The Exploit
The server sanitizes & and =, so we can't just send admin&role=admin. However, we control the length of the input. We can force specific parts of the server-generated text to fall into specific blocks.
This exploit is like building Lego: we will generate valid blocks from separate encryption requests and stitch them together so that they take the right shape.
First of all we want a ciphertext that ends exactly with role=.
Let's analyze the structure (assuming a 1-digit UID for simplicity):
email= (6 bytes) + [USER_INPUT] + &uid=1&role= (12 bytes)
We want the total length to be a multiple of 16 (e.g., 32 bytes) so that role= sits at the very end of Block 2.
$$32 - 6 (\text{header}) - 12 (\text{footer}) = 14 \text{ bytes}$$
If we send an email of 14 characters (e.g., ciaoo@mail.com), the blocks align perfectly:
- Block 1:
email=ciaoo@mail - Block 2:
.com&uid=1&role= - Block 3:
user+ padding
We keep Blocks 1 and 2.
Now we need a block that contains just the word admin (plus correct PKCS#7 padding).
We can generate this by putting admin inside the email field, but we must pad the start of the email so admin starts a fresh block.
email= is 6 bytes. We need 10 bytes of junk to fill the first block.
Input: a@mail.com + pad("admin")
- Block 1: `email=a@mail.com
- Block 2:
admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b(This is our payload!) - Block 3:
&uid=1&role=user...
We keep Block 2.
At the end, like a Lego, we concatenate the pieces:
$$(\text{Prefix Block 1}) + (\text{Prefix Block 2}) + (\text{Payload Block 2})$$
The resulting ciphertext will decrypt to:
email=ciaoo@mail.com&uid=1&role= + admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b
Here is the implementation of the exploit:
def cut_and_paste(oracle):
# prefix is going to became email=ciaoo@mail.com&uid=0&role=
crafted = "ciaoo@mail.com"
prefix = profile_for(crafted)[0:32]
crafted_admin = "a@mail.com" + pad(b"admin", 16).decode()
# second block contains exactly 'admin' + padding
admin_postfix = profile_for(crafted_admin)[16:32]
return prefix + admin_postfix
Post mortem
- Encryption $\neq$ Integrity: Just because an attacker cannot read the token doesn't mean they cannot modify it, in short, just sign your ciphertext with AES-GCM or HMAC.
- Block Independence is a Flaw: ECB's greatest weakness isn't just pattern leakage; it's the ability to treat blocks like Lego bricks. An attacker can reassemble them to create valid, authorized contexts that the server never generated.
Conclusion
From the analysis above, a critical lesson emerges: never use AES-ECB.
Beyond the specific algorithm, this highlights that vulnerabilities, as in any complex codebase, often stem from architectural complexity. A design choice that appears innocuous in isolation can open the door to critical exploits when integrated into a larger system.
This post was just a warm-up. In the next entry, we will cover more complex attacks against other modes, such as CBC and CTR.
Stay tuned.
Loading graph...