A writeup of the Cryptopals Crypto Challenge Set 4.
Recently, while working through a challenge on the Cyberchallenge portal, I found myself needing to implement a length extension attack on the SHA1 hashing algorithm.
Even though this is a well-known attack, my work ethic when it comes to understanding things led me to implement it from scratch. As luck would have it, Set 4 of the Cryptopals challenges covers this exact topic, which is why you are reading this writeup today.

For those unfamiliar, Cyberchallenge is an Italian national competition for university students focused on cybersecurity, CTFs, and offensive security. Participants compete in various categories, including cryptography, exploitation, reverse engineering, and web security.
In this post, I will show my solutions for the following challenges, adhering to the protocol described in the article about the second set.
- Break "random access read/write" AES CTR & CTR bitflipping
- Recover the key from CBC with IV=Key
- Implement a SHA-1 keyed MAC
- Break a SHA-1 keyed MAC using length extension
- Break an MD4 keyed MAC using length extension
- Implement and break HMAC-SHA1 with an artificial timing leak
- Break HMAC-SHA1 with a slightly less artificial timing leak
Levels 25 and 26 (CTR)
Prerequisites
To understand why these two challenges are nearly trivial, we need to understand Counter Mode (CTR).
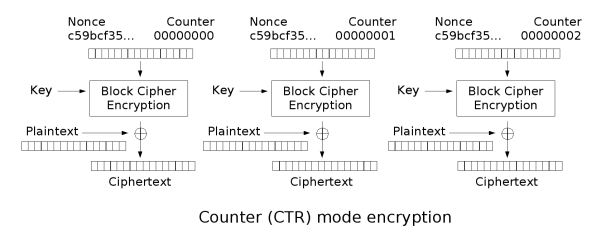
CTR mode transforms a block cipher into a stream cipher. Rather than encrypting the plaintext directly, it encrypts a counter value to generate a keystream, then XOR's that keystream against the plaintext:
$$\text{Keystream}_i = E_K(\text{nonce} \ || \ \text{counter}_i)$$ $$C_i = P_i \oplus \text{Keystream}_i$$
Unlike CBC, CTR requires no padding, is fully parallelizable, and crucially, encryption and decryption are the same operation: to decrypt, regenerate the same keystream and XOR again.
$$P_i = C_i \oplus E_K(\text{nonce} \ || \ \text{counter}_i)$$
The Attacks
Here is the code for bitflipping.
def ctr_bitflipping(ciphertext, known_bytes, known_bytes_pos, wanted_text):
assert len(wanted_text) == len(known_bytes)
recoverd_keystream = xor_bytes(
known_bytes, ciphertext[known_bytes_pos : known_bytes_pos + len(known_bytes)]
)
new_ciphertext = (
ciphertext[:known_bytes_pos]
+ xor_bytes(recoverd_keystream, wanted_text)
+ ciphertext[known_bytes_pos + len(known_bytes):]
)
return new_ciphertext
The attacks themselves are pretty trivial; what I would like to draw attention to is another property of AES-CTR: the ability to decrypt/encrypt at an arbitrary position $x$ simply by calculating the keystream for that specific offset.
An example of an application of this property could be the ability to encrypt various sectors of a disk. To study these types of problems, there is an actual branch of cryptography called disk encryption theory.
To perform the previously described operation safely, the standard used by LUKS, BitLocker, and FileVault is AES-XTS, which allows native random access and defines the concept of a tweak, a positioning parameter based on the disk's logical sector number.
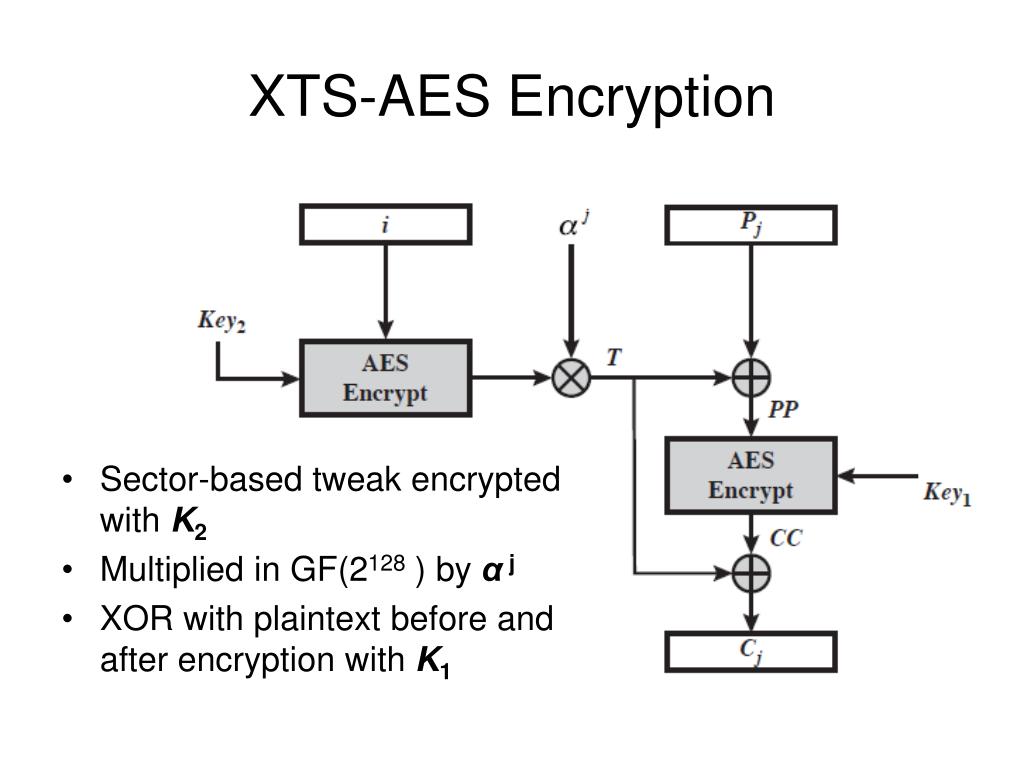 This ensures that the exact same file (for example, a block of zeros), if written to two different sectors of the disk, produces a completely different ciphertext, preventing recognizable patterns.
This ensures that the exact same file (for example, a block of zeros), if written to two different sectors of the disk, produces a completely different ciphertext, preventing recognizable patterns.
As for CTR bitflipping, a potential mitigation would have been to use a MAC to guarantee the authenticity and integrity of the message. Alternatively, an authenticated mode like AES-GCM or ChaCha20-Poly1305 could be used, avoiding the need to carry around extra information.
Level 27: Recover the Key from CBC with IV=Key
Prerequisites
Recall the CBC decryption formula:
$$P_i = D_K(C_i) \oplus C_{i-1}, \quad C_0 = \text{IV}$$
The Initialization Vector acts as the "previous ciphertext block" for the first block. In the standard specification it is a randomly generated nonce — unpredictable, but not secret. The IV is transmitted alongside the ciphertext and contributes no key material.
This level's vulnerability comes from a single misguided optimization: a developer chose to reuse the secret key as the IV, under the assumption that it saves the overhead of transmitting a separate nonce.
$$\text{IV} = K$$
This decision couples the key directly to the decryption of the first block, creating a path to full key recovery.
Problem Abstraction
KEY = os.urandom(16)
def encrypt(plaintext):
cipher = AES.new(KEY, AES.MODE_CBC, iv=KEY)
encrypted = cipher.encrypt(plaintext)
return {"ciphertext": encrypted.hex()}
def receive(ciphertext):
cipher = AES.new(KEY, AES.MODE_CBC, KEY)
decrypted = cipher.decrypt(ciphertext)
try:
decrypted.decode()
except UnicodeDecodeError:
return {"error": "Invalid plaintext: " + decrypted.hex()}
return {"success": "Your message has been received"}
Two oracles are available:
encrypt(P): encrypts any plaintext under $K$ with $\text{IV} = K$.receive(C): decrypts the ciphertext and checks if the result is valid ASCII. If not, it returns the raw decrypted bytes in the error message.
The vulnerability has two components working together:
- The key is used as the IV, stitching the secret into the decryption of Block 1.
- The error oracle leaks the raw plaintext back to the attacker.
The Exploit
As I usually do with certain problems, even though Cryptopals provided a high-level idea, I preferred to work out the solution on my own (since I had the necessary foundations to do so).
So, after staring at the AES-CBC diagram on Wikipedia for a few minutes and writing out the formula to try and isolate the key, it became clear that a single block isn't enough to perform the attack. However, if we look at the second block, the attack reveals itself naturally.
We choose a one-block plaintext $P_1 = \texttt{"A"} \times 16$ and encrypt it:
$$C_1 = E_K(P_1 \oplus K)$$
We then craft the two-block ciphertext $C' = C_1 \ || \ C_1$ and send it to receive. Following the CBC decryption formula:
$$P'_1 = D_K(C_1) \oplus K = P_1$$
$$P'_2 = D_K(C_1) \oplus C_1$$
Since $D_K(C_1) = P_1 \oplus K$, the second block expands to:
$$P'_2 = (P_1 \oplus K) \oplus C_1$$
Block 2 contains AES output XOR'd with known ciphertext bytes — almost certainly not valid ASCII — which triggers the error oracle and leaks $P'_2$. We then isolate $K$:
$$K = P'_2 \oplus P_1 \oplus C_1$$
chosen_first_pt = b"A" * 16
ct = encrypt(chosen_first_pt.hex())["ciphertext"]
crafted_ct = ct + ct
got = bytes.fromhex(receive(crafted_ct)["error"].split(":")[1])[16:32]
recovered_key = xor_bytes(xor_bytes(got, chosen_first_pt), bytes.fromhex(ct))
assert KEY == recovered_key
Levels 28 and 29: SHA-1 Keyed MAC and Length Extension
Prerequisites
A Message Authentication Code (MAC) provides two guarantees simultaneously: integrity (the message was not tampered with in transit) and authenticity (the message was produced by someone who knows the secret key $K$). Formally:
$$\text{MAC}(K, M) = T$$
Without knowing $K$, forging a valid tag $T$ for any new message should be computationally infeasible.
A naive construction is the prefix keyed hash:
$$\text{MAC}_{\text{naive}}(K, M) = H(K \ || \ M)$$
To understand why this is catastrophically broken, we must look at the internal structure of SHA-1.
The Merkle-Damgård Construction
SHA-1, like MD4, MD5, and SHA-256, is built on the Merkle-Damgård (MD) construction.
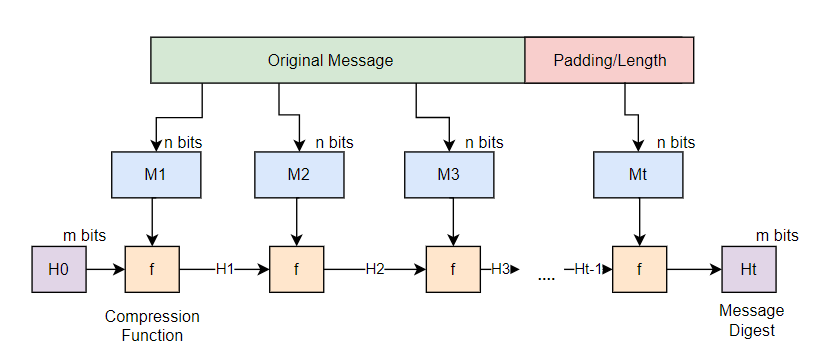
As shown in the image processing pipeline has three stages:
-
Padding: The message is padded deterministically to a multiple of 512 bits. The padding appends a
0x80byte, followed by enough0x00bytes, followed by a 64-bit big-endian encoding of the original message bit-length: $$M_\text{padded} = M \ || \ \texttt{0x80} \ || \ \underbrace{\texttt{0x00}\cdots}_ {k} \ || \ \text{len}(M) \cdot 8$$ We are going to call this deterministic suffix is called the glue padding. -
Compression: The padded message is split into 512-bit (64-byte) chunks. Each chunk is fed into a compression function $f$ alongside the current internal state, updating it.
-
Chaining: The internal state is a fixed-size vector of 32-bit words, initialized to known constants. After the last chunk, the final state IS the digest.
For SHA-1, the initial state is: $$h_0 = \texttt{0x67452301} $$ $$ h_1 = \texttt{0xEFCDAB89} $$ $$ h_2 = \texttt{0x98BADCFE} $$ $$ h_3 = \texttt{0x10325476} $$ $$ h_4 = \texttt{0xC3D2E1F0}$$
We have a critical invariant: the output digest fully encodes the internal state after the last compression round. If you have $\text{SHA1}(X)$, you know exactly what the internal state was after processing $X \ || \ \text{glue}(X)$, and you can resume the computation from there as if processing a continuation.
Problem Abstraction
We can query a function with any message $M$ and receive $T = \text{SHA1}(K \ || \ M)$.
The goal is to forge a valid MAC for $M \ || \ \text{glue} \ || \ \text{extension}$ without ever learning $K$. Concretely, we want to append a malicious suffix — say hacked — to an existing legitimate message and produce a tag the server will accept.
The Exploit
The attack is called Length Extension: we extend the signed message by appending arbitrary bytes while producing a valid MAC for the combined payload.
Here is the reasoning step by step:
-
Query the oracle for message $M$ and receive $T = \text{SHA1}(K \ || \ M)$.
-
Decode $T$ into $(h_0, h_1, h_2, h_3, h_4)$ by reading five consecutive big-endian 32-bit words from the hex digest. These are the exact SHA-1 internal state words after processing $K \ || \ M \ || \ \text{glue}(K \ || \ M)$.
-
Reconstruct $\text{glue}(K \ || \ M)$: the deterministic padding SHA-1 applied to $K \ || \ M$ when computing the original hash. We compute this precisely once we know $\text{len}(K)$ — which we may need to brute-force from 1 to 64 if it is unknown.
-
The forged message is: $M_{\text{forged}} = M \ || \ \text{glue}(K \ || \ M) \ || \ \text{extension}$
-
Compute the forged digest by initializing a fresh SHA-1 computation with the extracted state $(h_0 \ldots h_4)$ and processing only
extension, but telling the length counter that we have already processed $\text{len}(K \ || \ M \ || \ \text{glue})$ bytes. -
When the server computes $\text{SHA1}(K \ || \ M_{\text{forged}})$ it processes: $$K \ || \ M \ || \ \text{glue}(K \ || \ M) \ || \ \text{extension}$$ which is identical to what we computed — producing the same digest.
This is the key insight: SHA-1's compression function does not know or care where the padding ended. It sees the next 64-byte block and updates the state. If we initialize a fresh SHA-1 instance with the leaked state and process only the extension, we get a valid hash for the full concatenated message, as long as we set the internal length counter correctly.
To make this concrete, here is the full tweaked SHA-1 implementation. Two parameters make the attack possible:
def sha1_tweak(
message,
h0=0x67452301,
h1=0xEFCDAB89,
h2=0x98BADCFE,
h3=0x10325476,
h4=0xC3D2E1F0,
wanted_len=None,
):
original_byte_len = len(message)
original_bit_len = original_byte_len * 8
if wanted_len:
original_bit_len = wanted_len * 8 # lie: "I have processed wanted_len bytes so far"
message += b"\x80"
message += b"\x00" * ((56 - (original_byte_len + 1) % 64) % 64)
message += struct.pack(b">Q", original_bit_len)
for i in range(0, len(message), 64):
w = [0] * 80
for j in range(16):
w[j] = struct.unpack(b">I", message[i + j * 4 : i + j * 4 + 4])[0]
for j in range(16, 80):
w[j] = _left_rotate(w[j - 3] ^ w[j - 8] ^ w[j - 14] ^ w[j - 16], 1)
a, b, c, d, e = h0, h1, h2, h3, h4
for i in range(80):
if 0 <= i <= 19:
f, k = d ^ (b & (c ^ d)), 0x5A827999
elif 20 <= i <= 39:
f, k = b ^ c ^ d, 0x6ED9EBA1
elif 40 <= i <= 59:
f, k = (b & c) | (b & d) | (c & d), 0x8F1BBCDC
else:
f, k = b ^ c ^ d, 0xCA62C1D6
a, b, c, d, e = (
(_left_rotate(a, 5) + f + e + k + w[i]) & 0xFFFFFFFF,
a, _left_rotate(b, 30), c, d,
)
h0 = (h0 + a) & 0xFFFFFFFF
h1 = (h1 + b) & 0xFFFFFFFF
h2 = (h2 + c) & 0xFFFFFFFF
h3 = (h3 + d) & 0xFFFFFFFF
h4 = (h4 + e) & 0xFFFFFFFF
return "%08x%08x%08x%08x%08x" % (h0, h1, h2, h3, h4)
The compression rounds are standard SHA-1. The two non-standard lines are at the top: h0..h4 accept external values instead of the fixed initialization constants, and wanted_len overrides the bit-length encoded in the glue padding of the extension block. Together they let us start the hash exactly where the original digest left off, with the correct length field.
def gen_sha1_pad(msg_len):
original_bit_len = msg_len * 8
pad = b"\x80"
pad += b"\x00" * ((56 - (msg_len + 1) % 64) % 64)
pad += struct.pack(b">Q", original_bit_len)
return pad
def sha1_attack(oracle, key_len, first_msg, wanted_msg):
digest = bytes.fromhex(oracle(first_msg))
h0, h1, h2, h3, h4 = [int.from_bytes(digest[4 * i : 4 * (i + 1)]) for i in range(5)]
first_msg_internal = first_msg + gen_sha1_pad(key_len + len(first_msg))
wanted_len = key_len + len(first_msg_internal) + len(wanted_msg)
crafted_digest = sha1_tweak(wanted_msg, h0, h1, h2, h3, h4, wanted_len)
crafted_msg = first_msg_internal + wanted_msg
return crafted_msg, crafted_digest
gen_sha1_pad reconstructs exactly the bytes SHA-1 appended to $K \ || \ M$ when computing the original hash. sha1_tweak is a modified SHA-1 that accepts a custom initial state $(h_0 \ldots h_4)$ and a custom wanted_len, allowing us to inject the recovered state and resume hashing from the correct position. The wanted_len argument feeds the correct bit-length into the padding of the final extension block, ensuring the MAC verifies on the server side.
Level 30: MD4 Length Extension
Prerequisites
MD4 (Message Digest 4) is a precursor to MD5 designed by Ron Rivest in 1990. Its internal structure is also Merkle-Damgård, making it susceptible to the exact same length extension attack. Two implementation differences matter:
- Little-endian byte order: MD4 stores and recovers its internal state words as little-endian 32-bit integers. SHA-1 uses big-endian.
- Four state words: MD4's internal state is $(h_0, h_1, h_2, h_3)$ — 128 bits — versus SHA-1's 160 bits.
Problem Abstraction
Structurally identical to Level 29. We query the oracle for any message and receive the keyed MD4 MAC. The goal is unchanged: forge a valid MAC for an extended message without knowing $K$.
The Exploit
The attack is a direct port of sha1_attack. The only technical changes are the endianness of the state extraction and the padding formula.
def gen_md4_pad(msg_len):
ml = msg_len * 8
pad = b"\x80"
pad += b"\x00" * (-(msg_len + 1 + 8) % 64)
pad += struct.pack("<Q", ml) # little-endian
return pad
def md4_attack(oracle, key_len, first_msg, wanted_msg):
digest = bytes.fromhex(oracle(first_msg))
h0, h1, h2, h3 = [
int.from_bytes(digest[4 * i : 4 * (i + 1)], "little") for i in range(4)
]
first_msg_internal = first_msg + gen_md4_pad(key_len + len(first_msg))
wanted_len = key_len + len(first_msg_internal) + len(wanted_msg)
crafted_digest = MD4(wanted_msg, [h0, h1, h2, h3], wanted_len).hexdigest()
crafted_msg = first_msg_internal + wanted_msg
return crafted_msg, crafted_digest
The only structural difference from the SHA-1 attack is on the state extraction line: "little" instead of the implicit big-endian used for SHA-1. The padding formula likewise uses struct.pack("<Q", ml) (little-endian) versus SHA-1's struct.pack(">Q", ml) (big-endian). The conceptual lever is identical: decode the leaked state, reconstruct the glue padding, resume the hash, deliver the forged pair.
The elegance of this attack family is that the same conceptual lever — resuming a hash from a known intermediate state — breaks every Merkle-Damgård hash function. MD4, MD5, SHA-1, SHA-256, SHA-512: all fall to it. The fix is HMAC, which we encounter in the next level.
Levels 31 and 32: HMAC Timing Attack
Prerequisites
HMAC (Hash-based Message Authentication Code) was designed specifically to close the length extension vulnerability. Instead of the naive $H(K \ || \ M)$, it wraps the hash in a double-keyed construction:
$$\text{HMAC}(K, M) = H\bigl((K \oplus \text{opad}) \ || \ H((K \oplus \text{ipad}) \ || \ M)\bigr)$$
Where ipad = 0x36... and opad = 0x5c..., each repeated to fill the hash block size. This nesting makes the internal state of the outer hash inaccessible without knowing $K$, closing the extension attack.
HMAC is cryptographically sound. But a sound algorithm can still be broken if its implementation leaks information through a side channel, an observable artifact of the computation other than its output.
Timing side channels arise when the time to execute a function depends on secret input. The canonical example is a non-constant-time equality check: if the comparison short-circuits on the first mismatching byte, the response latency tells the attacker how many leading bytes were correct before the failure. This leaks one byte of information per query.
Problem Abstraction
def unsafe_compare(a, b) -> bool:
if len(a) != len(b):
return False
for x, y in zip(a, b):
if x != y:
return False
time.sleep(0.05) # 50ms artificial timing leak per matching byte
return True
The server exposes a /validate_file endpoint. Given a file and its file_checksum, it computes the HMAC of the file under a private key and compares it to the submitted checksum using unsafe_compare.
Every byte that matches before a mismatch injects a 50ms sleep. A checksum with $k$ correct leading bytes takes approximately $k \times 50\text{ms}$ longer to reject than one with $k - 1$ correct bytes.
HMAC-SHA1 produces a 20-byte tag. The timing oracle leaks the HMAC one byte at a time.
The Exploit
We recover the 20-byte HMAC position by position. For each index $i \in [0, 20)$:
- Bytes $[0, i)$ are already known from previous iterations.
- We try all 256 possible values for byte $i$, padding positions $[i+1, 20)$ with zeros (they will fail fast on mismatch — the zeros only need to not interfere with the current byte's timing signal).
- For each candidate, we send the HTTP request and measure the round-trip time.
- The candidate with the highest median response time has the most correct leading bytes. Since positions $[0, i)$ are already correct, the winning candidate is the one that pushed the comparison one step further before failing.
- Commit to this byte and advance to $i + 1$.
The use of median over multiple trials is essential: network jitter, OS scheduling, and garbage collection can produce timing outliers. The median suppresses them without the large sample count that the mean would require.
def side_channel_attack(
target_file: bytes,
hmac_size: int = 20,
trials: int = 5,
base_url: str,
) -> bytes:
recovered = bytearray(hmac_size)
file_hex = target_file.hex()
for pos in range(hmac_size):
print(f"Cracking byte {pos}/{hmac_size} ...", end="", flush=True)
best_byte = 0
best_median = -1.0
for candidate in range(256):
recovered[pos] = candidate
probe = bytes(recovered)
samples = []
for _ in range(trials):
t0 = time.perf_counter()
requests.get(
f"{base_url}/validate_file",
params={"file": file_hex, "file_checksum": probe.hex()},
timeout=hmac_size * 0.05 * 2 + 2,
)
samples.append(time.perf_counter() - t0)
med = statistics.median(samples)
if med > best_median:
best_median = med
best_byte = candidate
recovered[pos] = best_byte
print(f" 0x{best_byte:02x} (median={best_median:.4f}s)")
return bytes(recovered)
The total query count is at most $20 \times 256 \times \text{trials}$. With trials=5 and a 50ms sleep, cracking one byte requires up to $256 \times 5 = 1280$ requests. The full 20-byte HMAC requires up to 25,600 requests, but in practice converges faster since incorrect candidates fail at position $i$ with only a small fraction of the 50ms delay.
Level 32 reduces the sleep from 50ms to a few milliseconds, making the timing signal smaller relative to network jitter. The fix is to increase trials to 10-20: with enough samples, the median still reliably separates the correct byte from incorrect ones, but at the cost of an order of magnitude more requests. The attack structure is unchanged.
Conclusion
This set was quite simple compared to the third, but nonetheless instructive. In particular, it serves as a perfect example of how certain primitives may not be mathematically broken; rather, what truly matters is their implementation and the overall context in which they are used.
A single wrong assumption can compromise the entire system.
As for the side-channel attack, while real-world scenarios require many more considerations, it remains a great way to introduce the concept of lateral thinking, that is, obtaining and exploiting information that isn't explicitly provided.
I hope you learned something new today as well. See you in the next post! :)
Loading graph...